

I don't claim this is of much general interest but it came up in the PACE Trial where they gave percentages "improved" based on this. I am writing something so decided to research it more.
I'm writing something at the moment so doing a lot of reading.
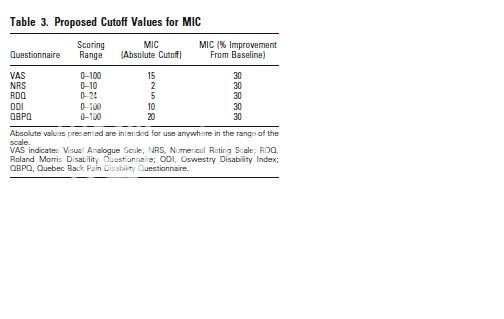
Those sorts of scores are quite a bit bigger than the 2 on the Chalder Fatigue Scale (0-33) and 8 on the SF-36 Physical Functioning scale (0-100) used in the PACE Trial.
For example, if one was to use the 30% of baseline values (mean SF-36 PF: 38.025, mean CFQ: 28.175), the values would have been:
SF-36 PF: 11.4075 (vs. 8)
CFQ: 8.4525 (vs. 2)
I'm writing something at the moment so doing a lot of reading.
Those sorts of scores are quite a bit bigger than the 2 on the Chalder Fatigue Scale (0-33) and 8 on the SF-36 Physical Functioning scale (0-100) used in the PACE Trial.
For example, if one was to use the 30% of baseline values (mean SF-36 PF: 38.025, mean CFQ: 28.175), the values would have been:
SF-36 PF: 11.4075 (vs. 8)
CFQ: 8.4525 (vs. 2)
Free full text at: http://journals.lww.com/spinejourna...Change_Scores_for_Pain_and_Functional.15.aspxInterpreting change scores for pain and functional status in low back pain: towards international consensus regarding minimal important change.
Spine (Phila Pa 1976). 2008 Jan 1;33(1):90-4.
Ostelo RW, Deyo RA, Stratford P, Waddell G, Croft P, Von Korff M, Bouter LM, de Vet HC.
Source
EMGO Institute, VU University Medical Centre, Amsterdam, The Netherlands. r.ostelo@vumc.nl
Abstract
STUDY DESIGN:
Literature review, expert panel, and a workshop during the "VIII International Forum on Primary Care Research on Low Back Pain" (Amsterdam, June 2006).
OBJECTIVE:
To develop practical guidance regarding the minimal important change (MIC) on frequently used measures of pain and functional status for low back pain.
SUMMARY OF BACKGROUND DATA:
Empirical studies have tried to determine meaningful changes for back pain, using different methodologies. This has led to confusion about what change is clinically important for commonly used back pain outcome measures.
METHODS:
This study covered the Visual Analogue Scale (0-100) and the Numerical Rating Scale (0-10) for pain and for function, the Roland Disability Questionnaire (0-24), the Oswestry Disability Index (0-100), and the Quebec Back Pain Disability Questionnaire (0-100). The literature was reviewed for empirical evidence. Additionally, experts and participants of the VIII International Forum on Primary Care Research on Low Back Pain were consulted to develop international consensus on clinical interpretation.
RESULTS:
There was wide variation in study design and the methods used to estimate MICs, and in values found for MIC, where MIC is the improvement in clinical status of an individual patient. However, after discussion among experts and workshop participants a reasonable consensus was achieved. Proposed MIC values are: 15 for the Visual Analogue Scale, 2 for the Numerical Rating Scale, 5 for the Roland Disability Questionnaire, 10 for the Oswestry Disability Index, and 20 for the QBDQ. When the baseline score is taken into account, a 30% improvement was considered a useful threshold for identifying clinically meaningful improvement on each of these measures.
CONCLUSION:
For a range of commonly used back pain outcome measures, a 30% change from baseline may be considered clinically meaningful improvement when comparing before and after measures for individual patients. It is hoped that these proposals facilitate the use of these measures in clinical practice and the comparability of future studies. The proposed MIC values are not the final answer but offer a common starting point for future research.
PMID: 18165753 [PubMed - indexed for MEDLINE]