Age appropriate comparisons for physical functioning, and other smoking guns?
Unimpressive results when compared to actual healthy populations, flawed definitions of "normal" for both the primary measures, questionable processing of potential participants, strawmanned version of pacing, omitted measurements, massive goalpost shifting, lack of actigraphy at follow up which they know would probably show no improvement, unexpected improvement trends in the "control" group (at least half as much as CBT/GET), possible reactivity bias (placebo response, observer-expectancy effect, Hawthorne effect), ceiling effect of the Chalder fatigue questionnaire, stated conflicts of interest in the paper itself, anything important I miss?
For anyone willing to look beneath the surface results, the PACE trial ironically shows that contrary to the uncritical hyperbole surrounding it, the rationale and effectiveness of CBT/GET is unconvincing even when the researchers have ample resources, a carefully selected cohort, a highly controlled environment using their best methods refined over 20 years, a chance to redefine expectations, and an opportunity to dress up the data to make it look better than it really is.
It really is incredible what these people are getting away with publishing and how everyone has been hoodwinked by it. How dare we question "respected experts" writing in one of the most "prestigious journals" in the world? The trial itself and the glowing reviews about its methodology and results, these are an insult to science and a disturbing punch to the face of the ME/CFS community. I hope sooner or later someone with academic clout will notice these flaws and publish a paper.
Unravelling the PACE trial obviously has revealed several major flaws which have been discussed on this thread (well done everyone!), but I think one of the most dramatic and visually impressive to casual observers would be the dubious definition of "normal" scores on the physical functioning subscale of the SF-36. As I said before, my friend became instantly suspicious after seeing that, and he isn't really all that interested in ME/CFS. I am wondering if this is a smoking gun, a clear example of ideological hyperbole and spin doctoring.
In Table 3 of the PACE paper, a rather "modest" improvement was reported for this measure after 52-weeks. On a scale of 0-100, the CBT group reported an additional 71 point improvement over "specialised medical care" (SMC), and 94 points for GET. 28% of those receiving CBT, and 30% for GET, were within "normal" ranges for both primary outcomes at 52 weeks, compared with 15% for SMC.
The defined threshold of "normal" scores for PF/SF-36 was "
equal to or above the mean minus 1 SD scores of the UK working age population of 84 (24) for physical function (score of 60 or more)", citing [Bowling A, Bond M, Jenkinson C, Lamping DL. Short form 36 (SF-36) health survey questionnaire: which normative data should be used? Comparisons between the norms provided by the Omnibus Survey in Britain, The Health Survey for England and the Oxford Healthy Life Survey. J Publ Health Med 1999, 21: 25570.]
http://jpubhealth.oxfordjournals.org/content/21/3/255.full.pdf
Did PACE use the data from this to calculate a new figure rather than use any single figure already given?
As others have already pointed out, Figure 1 of Bowling et al provides a histogram of physical functioning with a normal plot, for the general population. Because the distribution is heavily skewed towards the 100 point ceiling, 1 SD below the mean is an unusually low threshold, as the vast majority of people are scoring 80-100 points, and even then the trend is still at the top end of that range.
The average age of the participants in the PACE trial was 38 years (SD = 11?), so it is also worthwhile looking at these age groups in the general population rather than the entire "working age population".
Extracted from "Table 3: Mean (SD) scores for the SF-36 dimensions by age and sex and social class and health variables" (emphasis added):
[Physical functioning]
16-24: mean=95.5 (SD=12.1, n=204)
25-34: mean=94.5 (SD=13.5, n=415)
35-44: mean=93.3 (SD=13.4, n=319)
45-54: mean=87.2 (SD=20.9, n=297)
55-64: mean=78.0 (SD=26.3, n=297)
65-74: mean=72.7 (SD=26.7, n=281)
75-84: mean=57.9 (SD=28.6, n=296)
85+: mean=39.3 (SD=31.5, n=36)
Cut down activities because of illness (in last 2 weeks)...
Yes: mean=63.0 (SD=33.4, n=319)
No: mean=87.7 (SD=20.2, n=1722)
Long-term health problem...
Yes: mean=52.3 (SD=28.9, n=449)
No: mean=92.7 (SD=13.1, n=1590)
Using data for the 35-44 year old age group, mean=93.3 and SD=13.4, and using the PACE definition the threshold for normal, would be 80 not 60. AFAIK those figures for each age group are not even the healthy population, but the general population including people with illness, if so, even 80 is being too generous, although perhaps PACE wanted to imply that almost a third of the CBT and GET groups were "normal" enough to "work".
On average, the CBT and GET groups are still reporting similar PF/SF-36 scores as people in the population who have cut down activities because of illness in the last 2 weeks and/or have a long-term health problem and/or are well over 75 years old. 80 points is even higher than their original threshold of 75 points before it was changed to 60 points.
A number of PR forumites have expressed their suspicion that the PACE authors dishonestly presented the data. So I wondered what a more "honest" presentation would look like. Here is a modified version of Figure 2 from PACE, which has full scaling instead of being truncated as in the paper, and includes the above information:
Graphs really are our friend here. It is more effective to illustrate a reality check for the hyperbole using visual representations than a bunch of figures, it just takes a hell of a lot more time!
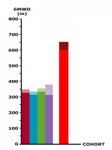
Another (unfinished) graph to show off would be the 6MWD scores. Here is a scale-accurate comparison of PACE participants vs healthy population. The lighter tips on the first 4 bars for the PACE groups represent the improvements, the red bar represents a conservative down-rounded figure of a 600m average for healthy females (since most PACE participants were female) and the dark red tip is a conservative average of 650m for healthy males.

If the rationale for GET was correct, we should expect a large improvement or even a return to the average of the healthy population, perhaps going further because of the "ex-patients" being encouraged to continue exercising as long as severe exacerbations are avoided. 12 months should be enough time to reverse the "deconditioning" that allegedly perpetuates symptoms of CFS. However on average, there was no such improvement in the PACE trial, so I think it is safe to say that the role of deconditioning, if any, is generally minor and has been grossly exaggerated. Despite the hyperbole, the PACE trial has instead demonstrated that the GET model endorsed by the researchers has been found wanting.
A picture can indeed be worth a 1000 words, but some statements can be better said with an audio file:
http://www.soundjay.com/misc/fail-trombone-02.mp3
In the editorial, Bleijenberg and Knoop make the absurd claim that "
PACE used a strict criterion for recovery"! PACE did originally had a more "strict" definition of "recovery" in the protocol, but since dropped it. Even people who have no exposure to ME/CFS should be wondering WTF? Bleijenberg and Knoop admit the evidence for "fear-avoidance" is weak, so they discuss "symptom focusing" instead. They don't seem too concerned that the research they cite also shows that these reported improvements to subjective fatigue are not resulting in increased activity. I think the biopsychosocialists are ignoring the objective measures so they can waffle on about "cognitions". They are very close to conceding this point, their own research shows it!
Just like the FINE trial can be used to kill off competition from the counselling alternative to CBT, the PACE trial will be used to kill off competition from the pacing alternative to GET. Perhaps they used a dubious equivalent of "pacing" to squash it? Bruce Campbell has noticed that elements of the CBT and GET used in the PACE trial are suspiciously similar to some aspects of pacing:
http://www.cfidsselfhelp.org/library/pace-trial-shows-two-forms-pacing-more-effective-third-type
(edit: I removed the following image for being too large, but it is worth checking out:
http://niceguidelines.files.wordpress.com/2011/02/photo-from-we-campaign-for-me.jpg)